
Machine learning is reshaping the pharmaceutical landscape, fuelling breakthroughs that once seemed out of reach. From predicting how new compounds interact with the body to streamlining clinical trials and personalising patient care, it now supports decisions across drug development and delivery.
How Machine Learning is Reshaping the Pharmaceutical Landscape
Machine learning is reshaping the pharmaceutical industry by advancing drug discovery, clinical trial efficiency, manufacturing, and personalised patient care. Using methods like supervised, unsupervised, reinforcement, and deep learning, it enables prediction of drug responses, optimisation of trial designs, identification of patient subgroups, and decoding of complex protein and chemical structures.
The real-world breakthroughs include Exscientia’s AI-designed drug entering clinical trials, Unlearn.AI’s use of digital twins to streamline trials, and DeepMind’s AlphaFold predicting millions of protein structures. However, challenges such as regulatory compliance, model interpretability, and validation remain critical.
Expanded Applications in Drug Discovery & Development
1. Machine Learning in Drug Discovery
Machine learning accelerates compound identification and development. Through virtual screening and predictive analytics, ML models analyse chemical and biological datasets to prioritise promising candidates, predict activity, potency, and toxicity, and minimise unnecessary wet-lab testing. Generative modelling supports de novo design, and data-driven insights aid repurposing.
2. Target Identification & Validation
One of ML’s capabilities lies in mining genomic, proteomic, and transcriptomic data to discover potential drug targets. Once identified, ML can simulate how these targets interact with various compounds, allowing for faster and more accurate validation.
3. Hit to Lead Optimisation
Once a potential "hit" compound is discovered, ML algorithms assist in refining it into a viable "lead" candidate. This helps align preclinical insights with patient outcomes and supports personalised therapies.
4. Integration of Real-World Evidence
Real-world evidence such as electronic health records, insurance claims, and patient registries are being integrated into discovery pipelines. This enables pharmaceutical companies to better align preclinical insights with actual patient outcomes, helping to personalise therapies and improve success rates in later phases of development.
What is Data Science?
Data science is the practice of extracting insights from data using statistics, computer science, mathematics, domain expertise, and machine learning. It uncovers trends, predicts outcomes, and supports evidence-based decisions.
In pharmaceuticals, where data from trials, EHRs, genomics, and wearables is abundant, data science is vital for managing complexity, spotting risks early, and improving patient outcomes.
Key Components of Data Science
Data science in the pharmaceutical industry integrates multiple components that collectively support the application of machine learning for research and healthcare. Data visualisation transforms complex datasets into graphical formats that reveal trends and anomalies, while data integration consolidates heterogeneous sources such as clinical trials, EHRs, genomics, and wearables into a unified framework.
Dashboards and business intelligence tools provide real-time and historical insights into key performance indicators, strengthening trial monitoring and decision-making. Distributed architectures such as Spark, Hadoop, and cloud-based systems enable efficient large-scale processing.
Automation through machine learning enhances efficiency by enabling anomaly detection, pharmacovigilance, and outcome prediction. Underpinning all these activities, data engineering provides the pipelines, quality assurance, and compliance structures to support reliable analytics.
What is Machine Learning?
Machine learning (ML) is a subset of artificial intelligence (AI) that enables computers to learn from data without being explicitly programmed. Instead of following static rules, ML models identify patterns and make decisions by analysing large datasets — continuously improving as they’re exposed to more data.
In the context of the pharmaceutical industry, machine learning is widely used. From predicting molecular interactions in early-stage drug discovery to detecting safety signals in post-market surveillance, ML offers automation, accuracy, and speed at a scale that traditional analytics cannot match.
How Machine Learning Works
At its core, machine learning relies on algorithms that build mathematical models based on sample data (known as “training data”). These models are then used to make predictions or decisions without being explicitly coded for every possible scenario.
Whether you’re classifying disease subtypes or forecasting patient responses to treatment, the process usually involves the following steps:
1. Data Preparation
In pharmaceutical machine learning projects, the foundation lies in robust data gathering and preprocessing. High-quality and diverse data—such as clinical trial results, lab tests, EHRs, genomics, and wearable sensor outputs—ensures that models are trained on rich and representative samples, enabling better learning and generalisation. However, raw data is often incomplete or inconsistent, containing missing values, duplicates, or outliers, which can compromise model performance.
2. Feature Engineering
This step involves selecting or transforming relevant input variables (features) that will help the model make accurate predictions. For example, combining dosage and patient weight into a single feature (mg/kg) may yield better results in a pharmacokinetics model.
3. Model Development
Model development involves selecting the appropriate machine learning approach—such as supervised learning for predicting outcomes, unsupervised learning for discovering hidden patterns, or reinforcement learning for optimising actions—and then training the chosen model to achieve high accuracy. During training, algorithms adjust internal parameters by processing data iteratively, minimizing errors, and refining predictions.
4. Evaluation and Insight
This stage focuses on assessing a model’s performance and translating its outputs into actionable knowledge. Evaluation is carried out using appropriate metrics—such as accuracy, precision, recall, AUC-ROC, or mean squared error—to ensure the model generalizes effectively to new data. In life sciences, metric selection is often application-specific, for example, emphasizing precision in cancer prediction to reduce false positives.
Enhanced Clinical Trial Processes
Clinical trials are time-consuming and complex. Many fail due to recruitment challenges, protocol deviations, or inaccurate outcome predictions. ML helps make trials faster, smarter, and more patient centric.
1. ML in Smarter Clinical Trial Management
Traditional clinical trial management often struggles with fragmented data, static protocols, and reactive decision-making. ML algorithms can process real-time data streams from EDCs, wearables, lab systems, and CROs to proactively identify risks, delays, or anomalies. This allows for predictive trial monitoring, where sponsors can course-correct before a problem derails the study. It benefits from real-time risk-based monitoring, which reduces protocol deviations and supports more efficient allocation of resources.
2. Optimising Patient Recruitment and Stratification
Patient recruitment, the leading cause of clinical trial delays, can be significantly improved with ML. By mining electronic health records, genomic databases, and social media, ML can identify patients who meet complex eligibility criteria and further stratify them into subgroups based on genetics, disease progression, or biomarker data.
3. Predicting Trial Outcomes
By learning from historical trial data, ML models can forecast potential outcomes, dropout rates, or adverse events for a new study. These predictions help stakeholders make evidence-backed decisions on whether to proceed, modify, or discontinue a trial. For example, ML can predict that a trial has a 70% chance of failing due to insufficient power, suggesting an early design revision. Benefits include reduced trial failure risk, early insights into efficacy or safety, and stronger support for go/no-go decisions.
4. Simulating Trial Designs for Efficiency
Machine learning enables the use of synthetic control arms and adaptive trial designs by drawing on historical and real-world data, reducing the need for large placebo groups. This approach shortens trial timelines, requires fewer patients, and strengthens both ethical and regulatory support, especially in rare or high-risk diseases.
Types of Machine Learning
Unsupervised Learning
Unsupervised learning finds patterns and group data without pre-assigned labels. By clustering inputs based on similarities, it uncovers hidden structures and insights. This approach has practical applications such as product recommendations on Amazon or content suggestions on Netflix and YouTube. 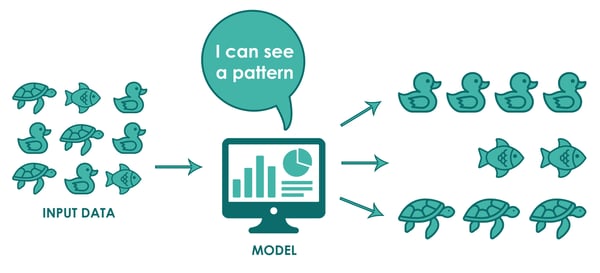
An area useful to medicines and medical research is suggesting references or related papers during drafting. When connected to relevant sources, ML can surface citations and related literature to support a hypothesis. In clinical trials, greater data transparency would further enhance its value. This type of ML is used by companies such as Benevolent AI, which formed a partnership with AstraZenca. However, it does not predict future outcomes.
Illustration of Unsupervised Learning
Spread of Zika Virus

Step 1
Input data on patients suffering from Zika virus from various locations in India.

Step 2
The algorithm analyses the data and clusters based on coastal region patients and inland regions.

Step 3
Based on the clustering density, we can identify where the Zika virus has spread to the most and an awareness campaign can be launched in the concerned regions.
This example illustrates that in unsupervised learning only clusters are formed, and we cannot apply it to prediction or outcome.
Real Life Example of Unsupervised Learning:
- We have Test A which is 95% accurate but 10 times costlier than normal blood tests.
- The aim: Find alternative lab tests to reduce patients going straight for an expensive Test A.
- Process:
- Step 1: Feed the past data (Test A and laboratory results) into the platform.
- Step 2: We run algorithm to form clusters.
- The Clusters identify abnormal results with high chances of positive test A, selecting patients for Test A and reducing cost.
Supervised Learning
Supervised learning is a task-oriented machine learning approach where algorithms are trained on labelled data to make predictions on new, unseen examples. Models learn from input-output pairs for classification or regression.
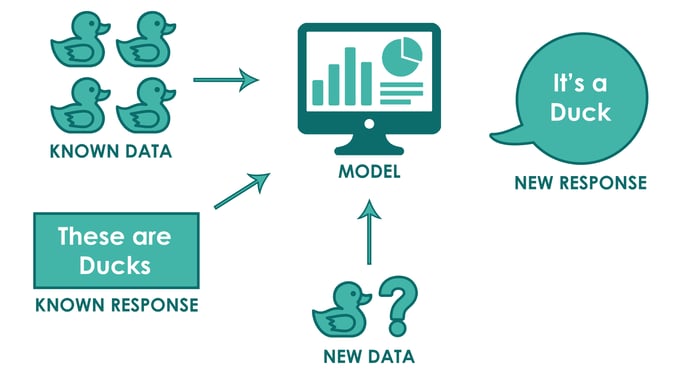
Illustration of Supervised Learning
Lab Tests for Anaemia
Step 1
An algorithm is trained about Hb level and corresponding output of either Anaemic or non-anaemic based on labelled data.
.
Step 2
Input data for patients with their Hb levels is fed into the algorithm.
Step 3
The algorithm analyses the patient’s data with Step 1 inputs.
Step 4
When new data is entered, the machine recognises the Hb level and generates a report on whether the patient is suffering from anaemia or not.
Real Life Example of Supervised Learning:
A clinical trials AI platform uses natural language processing (NLP) to help researchers manage workflows by identifying risk factors and optimising protocols.
Trained on billions of data points from past clinical trials, medical journals, and real-world sources, the system works by analysing uploaded research protocol documents, detecting potential risks or barriers, and reporting them to the user. It then provides recommendations to mitigate these risks and enhance the protocol design. Each time a new protocol is uploaded, the AI highlights possible challenges and suggests optimisations to improve trial success.
Reinforcement Learning
Reinforcement learning is a reward-based method where an algorithm learns through trial and error. Unlike unsupervised learning, it must make decisions that receive positive or negative feedback. Positive outcomes reinforce correct actions, while negative ones discourage mistakes, enabling continuous improvement.
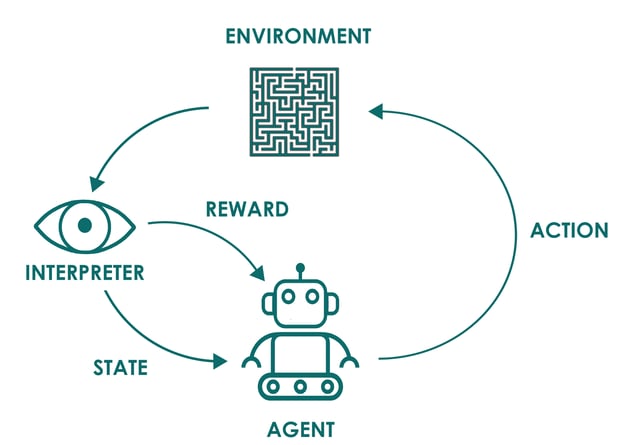
Reinforcement learning is often illustrated with game-playing systems that learn through rewards and penalties.
An Illustration as an Example from the Healthcare Sector
Diagnosis Based on X-ray

Step 1
Use a trained data labelled with correct diagnosis (Disease/ Normal) to train the algorithm.
Step 2
Load a new x-ray image; the model predicts the patient’s condition .

Step 3
Simultaneously the doctor diagnoses the patient condition by looking at the same x-ray and giving feedback on “Correctly diagnosed by ML” or “Incorrectly diagnosed by ML”.
Step 4
The feedback (or rewards) from the doctor makes the algorithm better for future diagnosis with less intervention.
Process Optimisation and Quality Control in Manufacturing
Machine learning (ML) is transforming pharmaceutical manufacturing by enabling smarter, faster, and more reliable processes. From real-time monitoring to predictive maintenance and advanced quality control, ML helps companies reduce production costs, improve efficiency, and ensure product consistency — while meeting strict regulatory standards.
1. ML in Pharma Manufacturing
Pharmaceutical manufacturing involves complex processes like synthesis, fermentation, purification, formulation, and packaging, which traditionally relied on manual checks. ML now analyses historical and real-time process data such as temperature, pressure, pH, and reaction times. By identifying hidden correlations, it recommends optimal settings to maximise efficiency, yield, and consistency.
For example, in tablet production, ML predicts how granule size or humidity will affect hardness and dissolution rate, ensuring quality standards are consistently met.
2. Real-Time Process Monitoring and Predictive Maintenance
With IoT integration, ML enables continuous monitoring of critical equipment such as centrifuges, reactors, and bioreactors. Predictive analytics detect anomalies early, preventing breakdowns, reducing unplanned downtime, and extending equipment life. Unlike fixed maintenance schedules, condition-based maintenance ensures interventions happen only when needed, saving costs.
3. AI-Driven Quality Control and Supply Chain Optimisation
Maintaining product quality is essential in pharma due to strict regulatory requirements. ML-driven computer vision systems and spectroscopic models inspect products in real time, detecting defects invisible to the human eye. These tools also analyse variability in raw materials and environmental conditions, ensuring compliance before batch release. For example, automated image recognition systems in vaccine production flag defective vials instantly, reducing waste and ensuring safety.
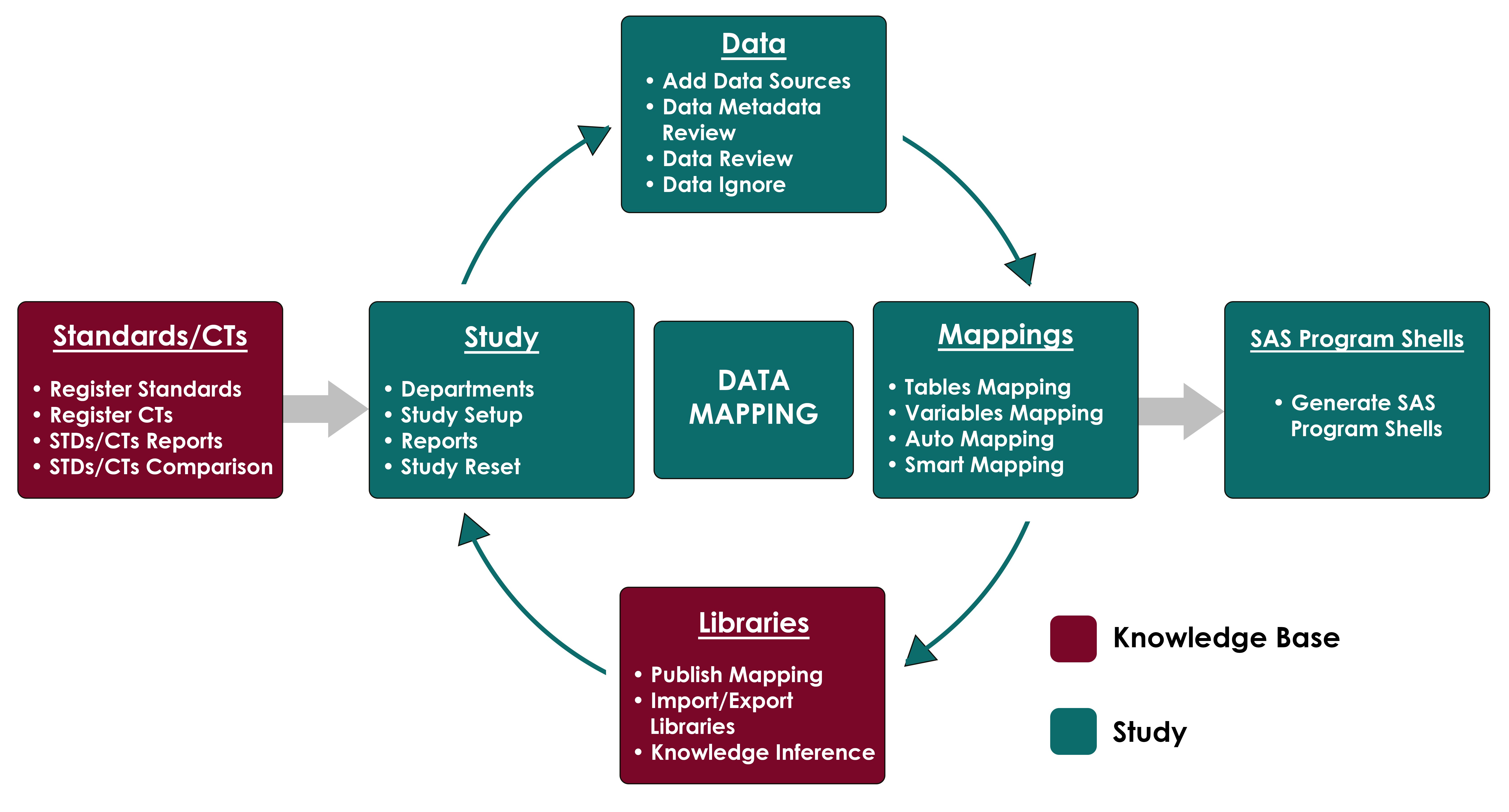
Data Mapper Tool: Process Flow
| Predictions: ['ae' 'cm' 'lb' 'fa' 'eg' 'ie'] Expected:['AE', 'CM', 'LB', 'FA', 'EG', 'IE'] | ||||
| Model_Matched_Term Model_Similarity NGram_Matched_Term NGram_Similarity | ||||
| Search_Term | ||||
| adverse2 | ae | 0.717276 | ae | 0.583333 |
| chemistry | lb | 0.515414 | lb | 1.000000 |
| conmed | cm | 0.703553 | cm | 1.000000 |
| electrocardiac | eg | 0.699650 | eg | 0.521739 |
| follow | fa | 0.683542 | fa | 1.000000 |
| inclusion | ie | 0.537428 | ie | 1.000000 |
Mapping raw healthcare data to CDISC SDTM and ADaM is complex, requiring accuracy and regulatory compliance. Manual mapping is slow and error-prone, while machine learning enables auto- and smart-mapping by reusing knowledge from past datasets. Using metadata, NLP, and standards libraries, ML predicts new mappings and reduces manual effort. Automated SAS programme generation further streamlines workflows, improving efficiency, quality, and compliance.
Process Flow in Clinical Data Standardisation Using ML and NLP
Standardising clinical trial data is a foundational step in ensuring regulatory compliance and data integrity. A Data Mapper Tool, powered by machine learning (ML) and natural language processing (NLP), enables automated and intelligent transformation of raw, heterogeneous data into industry-compliant formats like CDISC SDTM or ADaM — saving time, reducing human error, and improving traceability.
1. Mapping Raw Data to Industry Standards (e.g. CDISC SDTM/ADaM)
Raw-to-standard mapping is the process of converting raw clinical data variables (e.g., BP_SYS, AGE_YRS, TEST_DT) into their standard equivalents (VSORRES, AGE, LBDTC) per CDISC models and controlled terminology.
Traditional vs Modern Approach
| Step | Traditional Method | Data Mapper Tool |
| Variable matching | Manual, spreadsheet-based | Automated, suggestion-based |
| Codelist mapping | Manual lookup | Auto-link via CDISC/NCI |
| Metadata alignment | Needs SME | Pre-trained metadata engine |
| Audit trails | Created manually | Auto-generated |
Real Example:
- Raw variable: HT_CM
- Target CDISC: VSORRES (Height in cm), VSTESTCD="HEIGHT", VSORRESU="cm"
- Mapped using: variable name similarity + unit recognition + CDISC codelist alignment
2. Auto-Mapping and Smart Mapping Using ML and NLP
Modern Data Mapper tools go far beyond simple matching. They learn from historical datasets, apply fuzzy logic, and use language models trained on domain-specific terminology to interpret and suggest mappings.
Key Capabilities:
- ML-powered variable mapping: Learns frequent mappings across studies and sponsors
- NLP-based label parsing: Understands and dissects label text like “Patient’s systolic blood pressure in mmHg”
- Synonym recognition: Knows that “BLOOD GLUCOSE” and “GLUCOSE” map to the same standard
- Intelligent unit harmonisation: Maps mg/dL, mmol/L to appropriate LBORRESU
Example:
If a tool sees “Blood Glucose Fasting”, it maps it to:
- LBTESTCD = "GLUC"
- LBCAT = "CHEMISTRY"
- FAST = "Y"
Using prior mappings and NLP token matching.
3. Integration of Study Docs, Standards, and SAS Programme Generation
The power of Data Mapper tools lies in integration across multiple components of the study lifecycle.

Inputs Handled:
- Raw data (.xpt, .sas7bdat, .csv)
- Annotated CRFs (PDF/XML)
- CDISC Library (via API)
- Sponsor-defined value-level metadata (VLM)
- Standards repositories (CDASH, NCI Thesaurus)
Outputs Generated:
- Standardised SDTM or ADaM datasets
- SAS programmes with proper derivations
- define.xml draft with variable origins
- Automated traceability matrix
Case Study: CRO Implements Smart Mapping Tool
A large CRO processed 120 variables per study manually. With an AI-powered Data Mapper:
- 85% of mappings were auto suggested with 90% accuracy
- Time reduced by 70%
- Audit trail auto maintained, increasing regulatory readiness
Challenges in Pharma Industry to Implement Data Science
Data science offers major benefits, but adoption faces technical and cultural challenges.
1. Lack of Data Standards and Siloed Systems
One of the most persistent challenges is the fragmentation of data sources. Clinical, pre-clinical, manufacturing, sales, and patient-reported data often live in separate silos — stored in various formats, across geographies, or in vendor-owned systems.
This is a problem because incompatible data schemas often hinder data merging and analysis, requiring significant manual effort to reconcile terminology such as drug names, endpoints, and units. Regulatory submissions like CDISC SDTM and ADaM further demand standardized structures.
To resolve this, organisations can address data challenges by investing in data harmonisation platforms, implementing industry standards such as CDISC and HL7 FHIR, and promoting metadata-driven architectures to ensure consistency, interoperability, and scalability.
2. Ambiguity Around Data Accuracy and Quality
High-quality, clean, and reliable data is the backbone of effective data science. Unfortunately, pharma data often suffers from missing values, inconsistent labels, transcription errors, and outdated entries — particularly when collected across global trials or legacy systems.
Biased ML models reduce trust in decision-support tools and increase regulatory risks; for instance, inconsistent lab units in oncology trials can mislead progression metrics if not standardised. Data quality can be strengthened by introducing monitoring frameworks, automating validation and lineage tracking, and embedding data cleaning routines within the ETL (Extract, Transform, Load) process.
3. Operational and Talent Barriers
Pharmaceutical analytics workflows are still largely manual, with tasks like data wrangling, reporting, and generating SDTM/ADaM datasets consuming more time than the actual analysis. This slows decision-making, delays insights in areas such as clinical trials and pharmacovigilance and makes processes hard to scale. While automation through low-code platforms, AI-driven pipelines, and reusable templates can ease the burden, cultural resistance and skill gaps remain major challenges.
Many organisations face limited executive buy-in, fear of automation replacing roles, and a lack of hybrid talent that bridges life sciences and data science. Building trust in predictive models, fostering cross-training, and introducing “data translator” roles are key steps to overcoming these barriers.
Data Integration, Privacy, and Ethical Considerations
As pharmaceutical companies embrace machine learning (ML) and AI, data integration, privacy, and ethics become more critical. Managing large-scale, sensitive, complex data is a technical, regulatory, and ethical challenge.
1. Strategies for Managing Data Integration Challenges
Pharmaceutical data is often fragmented across clinical trials, EHRs, lab results, real-world evidence, and manufacturing systems, leading to inconsistent naming, lack of unified patient identifiers, platform incompatibilities, and siloed access. To overcome these challenges, companies are adopting centralised data hubs, standardised metadata catalogues like CDISC and MedDRA, and API-driven integrations for secure, real-time exchanges. Strong governance ensures clear roles, access policies, and stewardship.
2. Ensuring Data Quality and Regulatory Compliance
High-quality data is essential for accurate ML models, regulatory submissions, and clinical decision-making. Yet, pharma data is often plagued by missing values, duplicates, outdated entries, and format mismatches such as inconsistent units or date fields. Risks include misleading predictions, delays in approvals due to non-compliance, and patient safety concerns from incorrect outputs.
Solutions involve automated validation pipelines to flag anomalies during ingestion, and standardisation of units and terminologies. Regulatory alignment requires compliance with frameworks like GxP, HIPAA, GDPR, and 21 CFR Part 11 through integrated privacy features and validation steps. Auditable data pipelines are no longer optional, they are regulatory and operational necessities.
3. Addressing Privacy, Bias, and Transparency in ML Algorithms
Beyond integration and quality, ethical considerations are gaining prominence. As ML models become influential in areas like drug targeting, trial recruitment, and risk prediction, pharma companies must ensure that these models are fair, private, and explainable.
Privacy Challenges:
The use of sensitive patient data raises concerns about re-identification, and about cross-border data transfers and storage.
Privacy Measures:
- De-identification and Tokenisation: Remove personal identifiers and replace them with non-sensitive tokens.
- Differential Privacy: Introduce statistical noise into data to prevent reverse engineering of individual records.
- Secure Multi-Party Computation: Enable joint analysis across institutions without exposing raw data.
Bias and Fairness
ML trained on non-representative data can lead to biased outcomes affecting certain patient groups. To mitigate this, curate diverse datasets, conduct fairness audits across demographics, and apply rebalancing techniques during training.
Transparency and Explainability
Stakeholders—from clinicians to regulators—must understand how a model makes decisions, especially when lives are at stake.
To ensure transparency, organisations can use interpretable models such as decision trees or rule-based systems for critical applications, apply tools like SHAP or LIME to interpret black-box models, and maintain thorough documentation at every stage of model development and deployment.
Regulatory Processes for Approvals of AI/ML Products
As AI and ML become core to discovery, diagnostics, and digital therapeutics, regulators are adapting frameworks. However, navigating approvals for AI/ML-based products in healthcare remains complex and evolving.
1. Overview of Regulatory Challenges for AI/ML in Pharma
AI/ML-based products can adapt over time, rely on data-driven logic, and often function as “black-box” systems, creating unique hurdles in approval.
Key Challenges:
Algorithmic drift and adaptivity complicate validation after approval, and the lack of standardised frameworks hinders assessment of data quality, bias mitigation, performance, and real-world generalisability. Transparency and explainability are critical, yet many models lack clear decision rules. Large datasets from EHRs and wearables raise privacy concerns, driving the need for strict traceability and documented lineage.
2. Key Global Regulatory Developments
🇺🇸 FDA (U.S. Food and Drug Administration)
The FDA has been a front-runner in adapting regulatory processes for AI/ML-enabled medical devices.
🔹 Software as a Medical Device (SaMD)
- Many AI/ML systems fall under SaMD and must demonstrate clinical effectiveness, safety, and performance.
🔹 FDA’s Proposed AI/ML Framework (2021 Draft Guidance)
- Focuses on a “Total Product Lifecycle (TPLC)” approach.
Introduces a Predetermined Change Control Plan (PCCP) for defined post-approval updates.
🔹 Pre-Certification Pilot Program (Pre-Cert)
- Evaluated developers rather than just products.
- Aimed to allow trusted organisations to manage iterative updates without full re-approvals.
Although the programme ended in 2022, it informed future risk-based oversight models.
European Union: AI Act and Medical Device Regulation (MDR)
🔹 EU AI Act (in finalisation phase)
- Risk-based categorisation: high-risk AI (e.g., diagnostics, therapeutic recommendations) faces stringent approval rules.Requires transparency, explainability, human oversight, and data governance.
🔹 Medical Device Regulation (MDR)
- Encompasses software, including AI/ML systems used in diagnosis or treatment.
- Requires a clinical evaluation and conformity assessment, often through a Notified Body.
International and Patent Guidelines
🔹 WHO and ICH Discussions
Ongoing efforts to standardise AI evaluation frameworks for cross-border use.🔹 European Patent Office (EPO) and USPTO Guidelines
- AI/ML algorithms are patentable only if linked to a technical application (e.g., radiology).Pure mathematical models or general-purpose AI are not eligible.
- This impacts pharma startups seeking IP protection for AI products.
3. What Regulators Expect from AI/ML Developers
| Regulatory Focus Areas | Developer Responsibility |
| Model Transparency | Provide explainable models or tools like SHAP/LIME |
| Performance Metrics | Report sensitivity, specificity, AUC, PPV/NPV, etc |
| Data Provenance & Labelling | Maintain traceable, annotated, and auditable datasets |
| Post-Market Surveillance | Monitor real-world performance and report adverse events |
| Security & Bias Management | Document steps for securing data and mitigating bias |
AI and ML hold great promise across the pharmaceutical lifecycle, but without regulatory alignment, adoption can stall. To ensure success, companies developing AI-based products must engage early with regulators, maintain well-documented data and model lineage, and build human-centric approaches.
Future Trends & Broader Impact on Pharma
ML is evolving beyond data analytics and predictive modelling into more sophisticated, cross-functional applications. Key trends include:
1. Forward Looking Trends in Machine Learning for Pharma
Next-generation AI models, including foundation models, self-supervised learning, and few-shot learning, are accelerating drug discovery and extending AI applications to rare diseases with limited data. Multi-modal machine learning further enhances insights by integrating genomics, imaging, EHRs, and wearable data to improve clinical predictions and personalised treatment recommendations. In clinical trials, digital twins and real-time ML inference enable virtual patient simulations, dynamic monitoring, and more effective decision-making across trials, manufacturing, and patient follow-up.
2. Personalised Medicine and Precision Therapeutics
ML is the backbone of precision medicine—a healthcare model that tailors treatment to individual patients based on genetic, environmental, and lifestyle factors.
Applications of ML in Personalised Medicine:
AI is advancing personalised medicine through genomic data analysis to detect mutations and biomarkers that influence treatment pathways, patient stratification using ML algorithms to classify individuals by likely treatment response, and the development of companion diagnostics to identify which patients will benefit most from specific therapies. This approach is already showing success in oncology, where AI-driven biomarker identification is improving immunotherapy outcomes.
3. End-to-End AI Integration Across the Pharma Lifecycle
Pharmaceutical organisations are moving from isolated AI initiatives to full integration across every phase of the product lifecycle.
Integration Roadmap:
- Discovery: AI for target identification, compound generation, and screening
- Preclinical: Predictive toxicology and pharmacokinetics
- Clinical Trials: Adaptive design, recruitment prediction, and digital twins
- Manufacturing: Process optimization and predictive maintenance
- Regulatory Affairs: Automating documentation, submission tracking, and risk modelling
- Commercial Operations: Demand forecasting, patient segmentation, and AI-driven marketing
- Patient Monitoring: AI-based apps and tools for remote adherence and symptom tracking
This holistic AI strategy is helping pharma companies reduce development timelines, improve compliance, and increase return on investment.
4. Broader Impact on Operational Efficiency and Patient Outcomes
Machine learning is reshaping pharmaceutical operations by streamlining processes and enhancing compliance. Automated data pipelines cut down manual effort, intelligent supply chains optimize drug distribution, and regulatory intelligence tools keep strategies aligned with global standards. Real-world evidence (RWE) analysis further supports better post-market insights from EHRs, claims data, and patient registries.
For patients, ML enables faster access to therapies, more personalized treatments, improved adherence through AI-enabled tools, and reduced dropout rates in clinical trials. Together, these advances mark a shift toward a more efficient and patient-focused pharmaceutical ecosystem.
Conclusion
Machine learning is now a practical driver of innovation and efficiency. From early-stage drug discovery to post-market surveillance, ML is redefining how data is analysed, decisions are made, and treatments are delivered.
The transformation spans discovery, where ML accelerates target identification, screening, and toxicity prediction; clinical trials, where AI improves design, recruitment, and monitoring; manufacturing and quality control, where ML optimises production and maintenance; and regulatory affairs, which benefit from streamlined documentation, automated checks, and faster approvals.
Quanticate's statistical programming team have AI solutions to support our work and delivery to clients. If you have a need for these types of services please Submit an RFI below and a member of our business development team will be in touch with you shortly.
FAQs
- How is machine learning used in pharma?
ML is used throughout the pharmaceutical value chain to improve efficiency, accuracy, and decision-making. It helps identify candidates, predict trial outcomes, automate data processing, and personalise treatments. ML is also used in manufacturing to detect anomalies, optimise production, and maintain quality control, while in commercial functions, it enhances forecasting and customer engagement.
- How is AI being used in the pharmaceutical industry?
AI, which includes ML and other technologies, automates complex tasks and extracts insights from large datasets. In pharma, AI is applied in discovery, clinical trial optimisation, regulatory documentation, medical imaging analysis, pharmacovigilance, and real-world evidence analysis. AI also powers chatbots and virtual assistants for patient support, and drives smarter supply chain operations.
- What are the applications of ML in drug discovery?
In drug discovery, ML analyses biological and chemical datasets to identify novel targets, predict molecular properties, toxicity, and binding affinity, and generate new compound structures using generative models. It also classifies compounds as viable or non-viable based on historical success data, and helps prioritise candidates for laboratory testing and clinical evaluation.
- How has a pharma company applied machine learning to patient data?
Many pharmaceutical companies now use ML to analyse real-world patient data, including EHRs, genomics, and wearable device data. For example, some have developed models to predict responses to cancer therapies based on genetic profiles. Others use AI to identify patients at high risk of dropping out of trials or to detect early signals of adverse drug reactions. These applications support personalised treatment decisions and improve patient safety and retention.



.png?width=140&name=cdisc_gold_partner_80h%20(2).png)
