
The use of R programming in clinical trials has experienced significant growth recently, yet it remains less popular compared to traditional software like SAS or specialised clinical trial platforms. Despite its robust statistical capabilities and versatility, several factors contribute to its slower adoption in this field. Understanding these challenges, alongside recognising R’s growing role in the pharmaceutical industry, provides a comprehensive view of its current standing and future potential.
In this blog we will explore:
- What is R Programming?
- How is R used in Clinical Trials?
- Is R easier than Python/C++?
- R versus SAS for Tables, Listings and Figures
What is R Programming?
R is an open-source programming language that supports a wide range of statistical and graphical methodologies. It excels at data manipulation, calculation, and graphical display, making it a top choice for data analysis and statistical modelling.
How R is Used in Clinical Trials?
R is commonly used in various stages of clinical trials because of its strong statistical capabilities, versatility, and capacity to handle complex data processing. Here are a few summaries of how R is used in clinical trials:
Study Design and Planning
Designing and planning a study in R involves a series of steps, starting with defining what you want to achieve and the hypotheses you want to test. Once you have a clear idea of your objectives, you can move on to planning the statistical analyses you'll need and any simulations required to support your study. R offers a variety of tools and packages to help you with each of these steps, making it easier to design and execute your research effectively.
Data Management
Managing data in R means organising, cleaning, and getting your data ready for analysis. Good data management makes sure your data is accurate and consistent, so you can trust your results and perform reliable statistical analysis.
Descriptive Statistics
Descriptive statistics are essential for summarizing and making sense of your data. In R, you can calculate and visualize these statistics to understand the overall pattern, the average values, and how much the data varies. This helps you get a clear view of your data's main characteristics.
Efficacy Analysis
The study includes analysing both primary and secondary outcomes. This involves using survival analysis methods, such as Kaplan-Meier curves and Cox proportional hazards models, to examine time-to-event data. We also use mixed-effects models to analyse repeated measures and test for non-inferiority and equivalence to compare treatment effects. All of this can be programmed using R.
Safety Analysis
In clinical trials, safety analysis means evaluating any adverse events and other safety-related data to check if a treatment is safe for patients. In R, you can conduct this analysis using different statistical methods and visualizations to help identify and understand safety concerns.
Pharmacokinetic/Pharmacodynamic (PK/PD) Analysis
Pharmacokinetic (PK) and pharmacodynamic (PD) analysis are essential in drug development. PK analysis helps us understand how a drug is absorbed, distributed, metabolized, and eliminated by the body, while PD analysis shows how the drug affects the body. In R, you can perform these analyses using different statistical methods and specialized packages to get detailed insights into a drug's behaviour and effects.
Statistical Programming
Statistical programming in R means using the R language to analyse data, manage and visualize it, and create reports. R is a great tool for statisticians and data scientists because it has a wide range of libraries and is very flexible. Several R packages are commonly used, such as survival for analysing survival data, lme4 for mixed-effects models, ggplot2 for creating visualisations, tidyverse for data manipulation, emmeans for estimating marginal means, gt for generating tables, and ctrdata for handling trial data. These packages help with statistical modelling, data handling, visualisations, and reporting. When using R in clinical trials, there are often extra steps for validation and documentation to meet regulatory standards. Despite these requirements, R's capability to produce reliable and reproducible results makes it a valuable tool for analysing and reporting clinical trial data.
Graphics in R
R offers a wide range of options for visualizing data. You can start with basic plots in base R and move on to more advanced, interactive graphics using tools like ggplot2, lattice, and plot. By learning how to use these tools, you can create clear and engaging visuals that make it easier to analyse and present your data. Whether you're a data analyst, statistician, or researcher, mastering R’s graphics will help you effectively share insights and make informed decisions based on your data.
For example, the plot() function in R is not a single specified function, but rather a placeholder for a group of related functions. The specific function called will be determined by the parameters given. Here are some examples of outputs for plots in R.
 Figure 5. Multipage outputs for plots in R.
Figure 5. Multipage outputs for plots in R.
Is R easier than Python/C++?
Choosing between R and Python depends on your background and what you want to achieve. R is usually a better choice for those focused on statistics and data analysis because it has specialised packages and built-in functions for these tasks. Python, however, is more versatile and might be easier to learn if you have a general programming background or need to do more than just data analysis. If you're new to programming, Python might be simpler to pick up, while R is excellent for advanced statistical work.
Unlike R, C++ is a general-purpose language used for high-performance tasks and requires a deeper understanding of programming concepts. Both R and C++ use additional resources (packages in R and libraries in C++) to extend their functionality, While R is specialised for data analysis, C++ is better suited for software development and system programming, not for tasks such as clinical trial data analysis.
Watch our statistical consultant explore the most suitable manner of creating TLFs, be it R or SAS in the presentation below:
R versus SAS for Tables Listings and Figures (TLFs)
Everyone involved in any capacity in clinical trials reporting is aware of a sort-of self-proclaimed truth that can be broadly summarized as ‘Thou shall not have any software other than SAS’. Whilst this has been practically true for quite some time, somehow based on the misconception that regulators ‘strictly’ requested submissions to be made using SAS, other players have started to make their appearance in the pharmaceutical industry arena and draw attention of statistical programmers and statisticians alike. The most famous of these is most certainly the open software R, which has a long track record of usage in academia, both for applied and theoretical statistical research, and has been used to date also in the pharma industry, though its adoption in submissions has been hindered by the above described misconception.
Setting aside the validation part of the flow (which is a current hot area of discussion when it comes to R but will not be discussed here), moving from SAS to R for such a consolidated task as Tables, Listings and Figures (TLFs) creation does require some re-thinking. How the actual reporting works is a challenge as there is not a direct PROC REPORT counterpart that can be used straight away to export results to an output file, but that is the only real challenge. Since in most cases the efficiency with which a software can perform a task heavily depends on the ability of the end-user to exploit all of its features, using R efficiently (the same way we’ve been doing with SAS for quite a while now) simply implies getting used to it and getting to know all the ‘arrows in its quiver’ available to achieve a goal. In this blog we will first see how a specific TLF (including both summary and analysis sections) is usually generated in SAS and then we’ll see how the same table can be created and reported using R.
Generating an Analysis Table using SAS
No matter the software we use, i.e. SAS or R, to create a table or a listing (and to some extent also a figure) we’ll have to manipulate a source dataset (or more than one) to create a dataset/data frame that to a certain extent mirrors a given table specification, and then feed this dataset to a procedure (in SAS) or function (in R) that ‘translates’ the dataset into a neatly formatted table.
However, whilst this workflow appears rather slim, there’s a variety of decisional branches that need to be considered before choosing how to practically implement it. One key thing to decide is the actual format of the output table or listing: in many cases tables are created as plain text documents (.txt) which are then collated to a Word or PDF document using tools that are often external to the statistical software (e.g. VBA macros, UNIX scripts), but other viable options include either creating tables as Rich Text Format (.rtf) or .doc/.docx files to read into Microsoft Word straight away (and also in this case collation for reporting purposes is done outside of the software) as well as Portable Document Format (PDF) or html files.
For the sake of illustration, we will use data from a study on leprosy treatment described in Snedecor and Cochrane seminal Statistical Methods book [1]. The data has been arranged as a 3-columns dataset: Drug, Baseline and End of Treatment measurement (similar to a very simple CDISC ADaM BDS dataset, without subject ID as it’s not relevant for the example).
The goal is to produce a table so that for each of the 3 treatment arms, basic summary statistics are displayed as well as a section with a statistical analysis that compares drugs A and D to drug F (the control arm). If we wanted to create this kind of table using SAS we’d most likely use a combination of PROC MEANS/PROC SUMMARY/PROC UNIVARIATE for the first two sections (depending on our preferences or existing company-specific standard macros) and e.g. PROC GENMOD/PROC MIXED for the analysis section (again, depending on our preferences, though in this simple example there’s no clear advantage in using one vs the other) coupled with some data wrangling to put results together and have them in a dataset ready to feed into PROC REPORT, as in Figure 1 below.
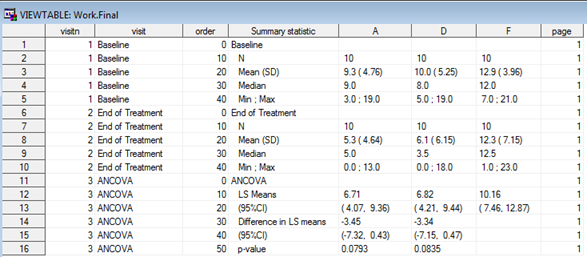
Figure 1. SAS dataset to create ANCOVA table
Whichever the output destination, the core PROC REPORT specifications will be pretty much the same, the main difference being the need to add some style commands when e.g. outputting to RTF to ensure the specifications are followed. The syntax for a plain text file here would look as follows:
title1 j = l "Protocol: Example Study" j = r "Page 1 of 1";
title2 j = l " ";
title3 "Table 1. Analysis of Covariance (ANCOVA) - leprosy treatment data" j = l;
proc report data = final headskip headline formchar(2)='_' spacing = 0 nowd center; column (" " page visitn order _label_ A D F);
define page / noprint order; define visitn / noprint order; define order / noprint order;
define _label_ / "" display width = 33 flow;
define A / "Drug A" display width = 22 center flow; define D / "Drug D" display width = 22 center flow; define F / "Drug F" display width = 22 center flow;
break after visitn / skip; compute after page;
line @1 "&line.";
line @1 "Generated on %sysfunc(date(),date9.) (%sysfunc(time(),time5.))"; line @1 "by &dir.table1.sas";
endcomp;
run;
The nice thing about the above commands is that the input dataset matches the shells only partially and full adherence can be obtained by using the plethora of built-in options that PROC REPORT features. Finally, in order to have the above sent to a .txt file we can wrap the PROC REPORT call between two PROC PRINTTO calls (the first starting printing to an output file, the second resuming printing to SAS listing), whereas for a .rtf file we could use the ODS RTF command (syntax skipped here), and for a .doc/.docx Word file the most recent addition ODS WORD (though the author hasn’t had the chance to use it yet). Figure 2 shows the resulting .txt file using the above PROC REPORT syntax.
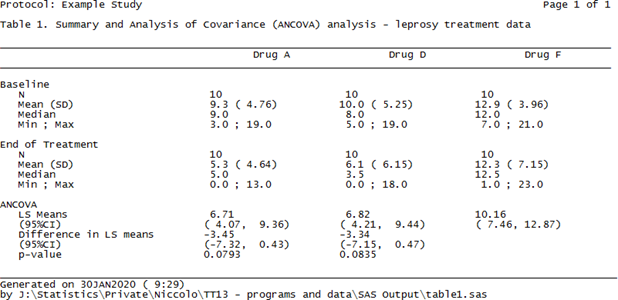
Figure 2. A .txt. table created using PROC REPORT
Generating an Analysis Table using R
A criticism often directed at R, in particular from die-hard SAS users, is that it’s too dispersed, with too many packages that quite often do the same things but provide results in a somehow inconsistent and incoherent manner. This can in fact be a great advantage when it comes to manipulating data frames to calculate simple summary statistics as well as fitting complex statistical models. Before moving onto the reporting bit, we will see how the summaries and ANCOVA section of the table can be quickly created using R to illustrate how this flexibility can be leveraged to achieve our purposes.
The summary statistics sections of the table are usually created in SAS by passing the source dataset to one of PROC MEANS, PROC SUMMARY or PROC UNVARIATE and the resulting dataset has to be re-formatted for our purposes. In order to do the same in R we can either manually write a function that calculates each summary and then arrange it, using e.g. tapply or by:
mean01 <- by(ancova, ancova$Drug, function(x){ means <- colMeans(x[,2:3])
})
mean02 <- as.data.frame(t(sapply(mean01, I)))
Note in the above the second and third column in the data are the baseline and post treatment values, respectively. Also we can re-arrange the source data in long-format (i.e. adding numeric (VISITN) and character (VISIT) variables identifying the time-point being summarized and then rely on one of the many wrapper functions such as ddply from the plyr package to calculate everything for us and put it in a nicely arranged dataset (similar to a PROC MEANS output):
descr01 <- ddply(ancova02, .(visitn, visit, Drug), summarize,
n = format(length(Drug), nsmall = 0),
mean = format(round(mean(aval), 1),
nsmall = 1), sd = format(round(sd(aval), 2), nsmall = 2),
median = format(round(median(aval), 1), nsmall = 1),
min = format(round(min(aval), 1), nsmall = 1), max = format(round(max(aval), 1), nsmall = 1))
This latter option was chosen here for it returns a readily usable data frame with already formatted summary statistics that then needs to undergo the usual post-processing steps to obtain an object that mimics the table shell. By using some functionalities of the tidyr package this can be easily achieved with no more programming efforts than it would using SAS.
The analysis section part can then be programmed in its core contents in a very compact manner:
model <- lm(PostTreatment ~ Drug + PreTreatment, data = ancova)
lsmeans <- emmeans(model, specs = trt.vs.ctrlk ~ Drug, adjust = "none")
lsm_ci <- confint(lsmeans)
The first line fits a linear model to the data; the second creates a list that contains two elements, the Least Squares (or Estimated Marginal, in the emmeans package) Means for each level of the factor ‘Drug’ alongside their 95% CI and their difference using a control reference class (in this case drug F); the third line is needed to create an object identical to the one created above that however stores the 95% CI for the differences instead of the p-value testing the hypothesis that the differences are equal to 0 (since the shell requires both). Once this section is post- processed using whichever combination of SQL-like language using sqldf or base R functionalities, we end up having the following data frame:

Creating this dataset took more lines of codes with SAS compared with R after excluding comments and blank lines as well as ‘infrastructure’ code (i.e. setting of libnames and options for SAS and loading of required libraries for R), and using a consistent formatting style (although R functions lend themselves more to compactness, i.e. one line of code for a function, much more than what SAS procedure statements need for ease of reading). Whilst this per se does not necessarily mean that R is more efficient than SAS (runtime on a large dataset or a more complicated table would be a much better indicator), it suggests that R offers an elegant and compact way of summarizing and analyzing data which is perfectly comparable to what SAS offers (and this is by no means a small thing!).
Notably, the first difference compared to SAS is that here we haven’t included the sorting variables VISIT/VISITN/ORD that were available in the SAS final dataset, the reason being that since they’re not going to be in the printed report there is no point in having them in (since it would be redundant including them only to have a selection that filters them out). Linked to this, the white lines between each section have been effectively added in as empty rows to mimic the table shell, something that in SAS we accomplished via the SKIP option in a BREAK BEFORE command. The general ‘take-home’ message is that the data frame to report needs to look exactly like the resulting table, and that includes eventual blank lines, order of the rows, ‘group’ variables (e.g. subject ID in listings where only the first occurrence row-wise is populated and the other are blanks).
At this point, having created the dataset in a rather simple manner, is it as simple to export it for reporting? As mentioned in the Introduction, there’s no R version of PROC REPORT however there are tools and functions that allow this task to be achieved using a comparable amount of programming as SAS with comparable quality. Whilst there are many options to achieve this, not all of them are as seamless to use as PROC REPORT and the resulting output is sometimes not fully fit for purpose. The combination of the officer and flextable packages, nevertheless, provides the user with a rich variety of functionalities to create nice-looking tables in Word format in a flexible manner.
The first step is to convert the data frame to report into an object of class flextable using the flextable function and then apply all styling and formatting functions that are needed to match the required layout. One useful feature of this package is that it allows the use of the ‘pipe’ %>%, a very popular operator that comes with the magrittr package and allows a neater programming by concatenating several operations on the same object. This translates in the below syntax:
summary_ft <- flextable(summary05) %>%
width(j = 2:4, width = 2) %>% width(j = 1, width = 2.5) %>%
height(height = 0.15, part = "body") %>%
align(j = 2:4, align = "center", part = "all") %>% align(j = 1, align = "left", part = "all") %>%
add_header_lines(values = paste("Table 1. Summary and Analysis of
Covariance (ANCOVA) analysis - leprosy data", strrep(" ", 30), sep = "")) %>%
add_header_lines(values = paste("Protocol: Example study", strrep(" ", 93), "Page 1 of 1", sep = "")) %>%
add_footer_lines(values = paste("Generated on ", Sys.time(), " by ", work, "Table1.R", sep = "")) %>%
hline_bottom(border = fp_border(color = "black"), part = "body") %>%
hline_bottom(border = fp_border(color = "black"), part = "header") %>% border_inner_h(border = fp_border("black"), part = "header") %>%
hline(i = 1, border = fp_border("white"), part = "header") %>% font(font = "CourierNewPSMT", part = "all") %>%
fontsize(size = 8, part = "all")
One great advantage of many functions within flextable is that they can be applied only to a subset of rows and/or columns by using standard R indexes, as we have done above to specify different column widths and alignments. The actual reporting to a Word document is done using the read_docx and body_add_flextable functions from the officer package: the first one opens a connection to a reference document (that in our case has been set to have a landscape orientation, as common for TLFs) and the second adds the flextable object created above to the document. The actual reporting is then done using the standard print function:
doc <- read_docx("base.docx") %>% body_add_flextable(value = summary_ft)
print(doc, target = "Table1.docx")
The resulting output is displayed in Figure 3 below.

Figure 3. A .docx table file created using flextable and officer
In the above program there are a few things worth mentioning before we do an actual compare with SAS:
- the two add_header_lines calls are in a somewhat reverse order since we specify the table title before the so- called page header, but that’s because the function allows to place extra lines either at the top of the header (as default) or at the bottom, and by doing as above we first write the table title above the table, and then above the title we write the protocol name and the page number;
- the horizontal lines in the header need to be sorted out in a slightly convoluted manner: the second hline_bottom function call adds the line under the column names, the border_inner_h call adds horizontal line between all rows of the header, however since we don’t want any line to be shown between the page header and the table title we need an hline call that applies a white border at the bottom of the first header row, resulting in the table shown above;
- the result of Systime() is slightly different from SAS.
As introduced at the beginning of this blog, the reporting of Tables using R is a conceptually different process compared to SAS, however we can see that the key options that exist in PROC REPORT also exist in the flextable package, as mentioned in Table 1. There are other features (e.g. the possibility to change font, font size, etc.) that can be mapped between the two software, but those mentioned below cover the most important ones.
Table 1. Key reporting features – comparison between PROC REPORT and flextable
|
Scope |
PROC REPORT option/statement |
FLEXTABLE function |
|
Aligning columns |
center/left/right options in the define statement |
align function |
|
Width of columns |
width option in the define statement |
width function |
|
Line above column names |
‘ ’ in the column statement (see proc report on page 2) |
border_inner_h function |
|
Line below column names |
headline option in proc report statement |
hline_bottom function |
|
Line at the bottom of the table |
compute after _page_/<page- variable> block |
|
|
Add footnotes/titles |
footnoten/titlen statement /line statement in a compute after block (footnotes only) |
add_header_lines (titles) add_footer_lines (footnotes) |
|
Multicolumn header |
Embed columns in brackets: (“header” col1 col2) |
add_header_row using the colwidths option |
|
Skip lines |
break after <var> / skip |
none |
|
Page break |
break after <var> / page |
body_add_break (from the officer package) |
One specific mention is needed for the last two rows here, i.e. the chance to ‘break’ the table in different ways, either by adding blank lines between rows or by moving to another page. Fixing the first issue in R is relatively easy, as we mentioned before, whereas for the second one a different approach needs to be taken that involves writing a general function that iteratively prints pages to the reference Word document and then adds page breaks. To do this we first need to create a variable page (as we’d commonly do in SAS if we wanted to avoid odd page breaks), and then the function could look as follows:
page.break <- function(data, pagevar = "page"){
## Identify which variable stores the page number and how many pages
npage <- 1:max(data[,pagevar])
which.pg <- which(names(data) == pagevar)
## Define the flextable object separately for each page
for (i in npage) {
## Create the Page x of y object for the title and identify which rows to display based on page number
npg <- paste("Page", i, "of", max(npage), sep = " ") rows <- which(data[,which.pg] == i)
#flextable object definition (use the npg object to ensure the correct Page x of y header line is added
## Print the object out: if it is the first one add to base.docx otherwise add to the document with previous pages printed
if (i == 1) {
doc <- read_docx("base.docx") %>% body_add_flextable(value = summary_ft)
fileout <- "Table1.docx" print(doc, target = fileout)
} else {
doc <- read_docx("Table1.docx") %>% body_add_break() %>% body_add_flextable(value = summary_ft)
fileout <- "Table1.docx" print(doc, target = fileout)
}
}
}
Once a page variable is added to the reporting dataset to have the ANCOVA section displayed on a separate page and the above function is applied, the result is the one displayed in Figure 4 (the actual spaces between tables have been reduced to fit this blog).
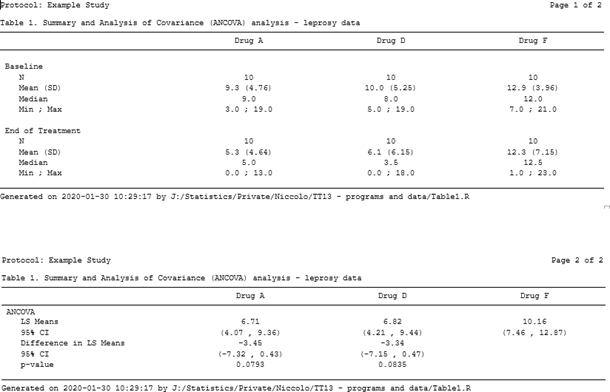
Figure 4. Multipage table using flextable and officer
The only drawback with the above is that it implies having a page variable that correctly splits rows such that when printing there’s no overflow to the next page, although this might reasonably be an issue only with long tables such as Adverse Events or listings). In general, anyway, the two packages combined offer a great degree of flexibility that allows one to reproduce a table as with SAS using a somehow more explicit report definition compared to PROC REPORT, and the actual amount of programming required is similar to SAS.
Can R Rival SAS in TLF Creation?
Moving from SAS to R for TLFs implies some rethinking of the way we approach clinical trial reporting. Whilst this is indeed true, as the previous section has shown, it is important to understand that this re-thinking is in fact only minimal and somehow superficial: we’ll still be creating output datasets that other programmers will try to match on (using either all.equal or compare_df) and then exporting this to a suitable document outside of the statistical software. This being the case, the only question worth asking is ‘Why?’
In the author’s view there are many answers to this question which we've summarised in the table below:
|
Aspect |
R |
SAS |
|
Purpose |
Designed for flexible data analysis and visualization. |
Specialized in clinical trial data management and TLF creation. |
|
Customization |
Highly customizable with packages like rmarkdown, knitr, and ggplot2 for creating TLFs. |
Provides built-in procedures and macros specifically tailored for TLF outputs. |
|
Ease of Use |
Requires coding and knowledge of packages; steep learning curve for complex TLF creation. |
Generally easier for TLF creation with user-friendly procedures and graphical interfaces. |
|
Flexibility |
Extremely flexible, allowing for extensive customization and automation of TLF creation. |
Less flexible but offers standardized, reliable solutions for TLF generation. |
|
Integration |
Integrates well with various data analysis tools and can produce high-quality, customized reports. |
Seamless integration with clinical trial data systems and regulatory reporting requirements. |
|
Regulatory Compliance |
Capable of meeting regulatory requirements with careful setup and validation. |
Well-established for regulatory compliance and widely used in regulatory submissions. |
|
Community Support |
Active community with numerous packages and resources for TLF creation. |
Strong support with extensive documentation and industry-specific resources. |
|
Cost |
Open-source and free, which can be advantageous for budget-conscious projects. |
Commercial software with associated licensing costs. |
The main reason (for the author) is the immense breadth of statistical methods and procedures available in R compared to SAS: mixed models, survival analysis, parametric and non-parametric tests, and many others. All these are readily available and have contributions from some of the most senior members of the R community (if not some of the main experts on the topic in the world). Plus, computationally intensive techniques (such as bootstrap or permutations) can be implemented in a more intuitive manner than with
There are certainly some cases where attempting to recreate SAS results using R and vice versa has generated more than one migraine, but in most cases this occurs because the assumptions and default implementations differ (e.g. the optimization method for a given regression) rather than because of real differences. Many of these have been documented on the internet in mailing lists and help pages, and no doubt that the more the industry starts making more consistent use of R more scenarios will emerge, thus prompting better knowledge of both software.
Conclusion
The uptake of R as software of choice within pharmaceutical companies and Contract Research Organizations (CROs) is something that many doubted to see during their lifespan, however things are rapidly moving even in the pharmaceutical industry. Nevertheless, many misconceptions about R still exist, not least whether it’s a tool suitable for creating submission-ready deliverables such as TLFs. In this blog we have seen that R can be an extremely powerful tool to create Tables and Listings using the officer and flextable packages and tools already available (and for great figures ggplot2 is available), and that by leveraging its high flexibility it is possible to obtain high- quality results with comparable efficiency and quality to standard SAS code.
All in all, the current R vs SAS debate is not fair: SAS has been used in the industry for decades now and its pros and cons are our bread and butter now, but the same can’t be said about R which is often met with prejudice due to its open-source nature. Hopefully the above example and considerations have provided a different angle to this quarrel and why it does not need to be a quarrel at all.

Turn your validated trial data into interpretable information ready for biostatistical analysis. Using R Programming or SAS, Quanticate can help you better understand the effect of your investigational product and it’s safety and efficacy against your trial hypothesis with the creation of analysis datasets and production of TLFs. Request a consultation below and a member of our Business Development team will be in touch with you shortly.
References
[1] Snedecor GW, Cochran WG. Statistical Methods, sixth edition. Ames: Iowa State University Press
Appendix
Overview of the R packages used in this blog.
|
Package |
Description |
|
dplyr |
A fast, consistent tool for working with data frame like objects, both in memory and out of memory. |
|
plyr |
A set of tools that solves a common set of problems: you need to break a big problem down into manageable pieces, operate on each piece and then put all the pieces back together. For example, you might want to fit a model to each spatial location or time point in your study, summarise data by panels or collapse high-dimensional arrays to simpler summary statistics. |
|
tidyr |
Tools to help to create tidy data, where each column is a variable, each row is an observation, and each cell contains a single value. 'tidyr' contains tools for changing the shape (pivoting) and hierarchy (nesting and 'unnesting') of a dataset, turning deeply nested lists into rectangular data frames ('rectangling'), and extracting values out of string columns. It also includes tools for working with missing values (both implicit and explicit). |
|
emmeans |
Obtain estimated marginal means (EMMs) for many linear, generalized linear, and mixed models. Compute contrasts or linear functions of EMMs, trends, and comparisons of slopes. Plots and compact letter displays. |
|
sqldf |
The sqldf() function is typically passed a single argument which is an SQL select statement where the table names are ordinary R data frame names. sqldf() transparently sets up a database, imports the data frames into that database, performs the SQL select or other statement and returns the result using a heuristic to determine which class to assign to each column of the returned data frame. |
|
flextable |
Create pretty tables for 'HTML', 'Microsoft Word' and 'Microsoft PowerPoint' documents. Functions are provided to let users create tables, modify and format their content. It extends package 'officer' that does not contain any feature for customized tabular reporting and can be used within R markdown documents |
|
officer |
Access and manipulate 'Microsoft Word' and 'Microsoft PowerPoint' documents from R. The package focuses on tabular and graphical reporting from R; it also provides two functions that let users get document content into data objects. A set of functions lets add and remove images, tables and paragraphs of text in new or existing documents. When working with 'Word' documents, a cursor can be used to help insert or delete content at a specific location in the document. The package does not require any installation of Microsoft products to be able to write Microsoft files. |
|
magrittr |
Provides a mechanism for chaining commands with a new forward-pipe operator, %>%. This operator will forward a value, or the result of an expression, into the next function call/expression. |



.png?width=140&name=cdisc_gold_partner_80h%20(2).png)
